[MLOps] Katib 예제
Katib 를 이용해서 하이퍼 파라미터 튜닝을 합니다.
학습 코드 작성하기
- 하이퍼 파라미터를 입력받기 위해
argparse라이브러리를 사용합니다. 여기서는 학습률, 드롭아웃, 옵티마이저만 입력받도록 하겠습니다. - 메트릭 출력 시,
RFC-3339포맷으로 시간을 출력하면 Katib 대시보드에서 시간대별 accuracy 를 볼 수 있습니다.
아래 코드는 숫자 mnist 데이터를 가지고 간단한 신경망으로 학습하는 예제입니다.
import argparse
from datetime import datetime, timezone
import numpy as np
import tensorflow as tf
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--learning_rate", default=0.01, type=float)
parser.add_argument("--dropout", default=0.2, type=float)
parser.add_argument("--optimizer", default="adam", type=str)
args = parser.parse_args()
mnist = tf.keras.datasets.mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images = training_images / 255.0
test_images = test_images / 255.0
validation_images = training_images[-10000:]
validation_labels = training_labels[-10000:]
training_images = training_images[:-10000]
training_labels = training_labels[:-10000]
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dropout(args.dropout),
tf.keras.layers.Dense(10, activation="softmax")
])
model.compile(
optimizer=args.optimizer,
loss="sparse_categorical_crossentropy",
metrics=["accuracy"]
)
class KatibMetricLog(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
# RFC 3339
local_time = datetime.now(timezone.utc).astimezone().isoformat()
print("\nEpoch {}".format(epoch+1))
print("{} accuracy={:.4f}".format(local_time, logs['accuracy']))
print("{} loss={:.4f}".format(local_time, logs['loss']))
print("{} Validation-accuracy={:.4f}".format(local_time, logs['val_accuracy']))
print("{} Validation-loss={:.4f}".format(local_time, logs['val_loss']))
callbacks = KatibMetricLog()
model.fit(
training_images,
training_labels,
batch_size=64,
epochs=10,
validation_data=(validation_images, validation_labels),
callbacks=[callbacks]
)
도커 이미지 만들기
학습 코드를 도커 이미지로 만듭니다.
FROM tensorflow/tensorflow:2.1.0-py3
RUN mkdir -p /app
ADD mnist_train.py /app/
ENTRYPOINT ["python", "/app/mnist_train.py"]
YAML 파일 작성
이제 Katib 에 배포를 위한 YAML 작성이 필요한데요. 조금 복잡하지만 차근차근 살펴봅시다.
apiVersion: "kubeflow.org/v1beta1"
kind: Experiment
metadata:
namespace: kubeflow
name: katib-example
여기까지는 복잡할 게 하나도 없죠. 이어서 등장하는 spec 이 조금 복잡합니다.
먼저 목표를 지정해주어야 하는데요, 주요 목표와 보조 목표를 적어줍니다. 여기서는 검증셋의 정확도를 주요 목표로 잡고 그 값을 0.99 로 정했습니다. 보조 목표를 훈련셋의 정확도로 지정했습니다.
objective:
type: maximize
goal: 0.99
objectiveMetricName: Validation-accuracy
additionalMetricNames:
- accuracy
다음으로는 하이퍼 파라미터 값을 어떻게 정할 지 그 알고리즘을 선정해야 하는데요. 여러 가지 알고리즘이 있지만 저는 random 방식을 사용하겠습니다.
algorithm:
algorithmName: random
실험을 총 몇 번 수행할 지, 동시에 몇 개의 실험을 수행할 지 등을 아래와 같이 작성합니다.
parallelTrialCount: 2
maxTrialCount: 10
maxFailedTrialCount: 1
parameters 에서는 하이퍼 파라미터로 사용할 이름과 그 범위를 지정합니다. 우리는 random 알고리즘 방식을 사용했기 때문에 이 범위 내에서 무작위로 선정하여 실험을 수행합니다.
parameters:
- name: learning_rate
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.2"
- name: dropout
parameterType: double
feasibleSpace:
min: "0.1"
max: "0.5"
- name: optimizer
parameterType: categorical
feasibleSpace:
list:
- sgd
- adam
- ftrl
TrialTemplate 에서는 위에서 만든 학습 이미지와 명령문, 하이퍼 파라미터 설명 등을 추가로 작성합니다.
trialTemplate:
primaryContainerName: training-container
trialParameters:
- name: learning_rate
description: Learning Rate
reference: learning_rate
- name: dropout
description: Dropout
reference: dropout
- name: optimizer
description: Optimizer
reference: optimizer
trialSpec:
apiVersion: batch/v1
kind: Job
spec:
template:
spec:
containers:
- name: training-container
image: katib-example:0.0.1
command:
- "python3"
- "/app/mnist_train.py"
- "--learning_rate=${trialParameters.learning_rate}"
- "--dropout=${trialParameters.dropout}"
- "--optimizer=${trialParameters.optimizer}"
restartPolicy: Never
아래는 위에서 설명드린 것들의 전체 코드 입니다.
# file: "katib_example.yaml"
apiVersion: "kubeflow.org/v1beta1"
kind: Experiment
metadata:
namespace: kubeflow
name: katib-example
spec:
objective:
type: maximize
goal: 0.99
objectiveMetricName: Validation-accuracy
additionalMetricNames:
- accuracy
algorithm:
algorithmName: random
parallelTrialCount: 2
maxTrialCount: 10
maxFailedTrialCount: 1
parameters:
- name: learning_rate
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.2"
- name: dropout
parameterType: double
feasibleSpace:
min: "0.1"
max: "0.5"
- name: optimizer
parameterType: categorical
feasibleSpace:
list:
- sgd
- adam
- ftrl
trialTemplate:
primaryContainerName: training-container
trialParameters:
- name: learning_rate
description: Learning Rate
reference: learning_rate
- name: dropout
description: Dropout
reference: dropout
- name: optimizer
description: Optimizer
reference: optimizer
trialSpec:
apiVersion: batch/v1
kind: Job
spec:
template:
spec:
containers:
- name: training-container
image: katib-example:0.0.1
command:
- "python3"
- "/app/mnist_train.py"
- "--learning_rate=${trialParameters.learning_rate}"
- "--dropout=${trialParameters.dropout}"
- "--optimizer=${trialParameters.optimizer}"
restartPolicy: Never
배포 및 Katib 대시보드에서 확인
kubectl을 통해 배포를 진행합니다.
kubectl apply -f katib_example.yaml
katib-ui를 통해 대시보드에서 진행 상황을 확인할 수 있습니다.
kubectl port-forward svc/katib-ui -n kubeflow 8202:80
http://localhost:80/katib 에 접속해봅시다. 좌측 메뉴에서 HP - Monitor 를 누르면 방금 배포한 실험이 보입니다.
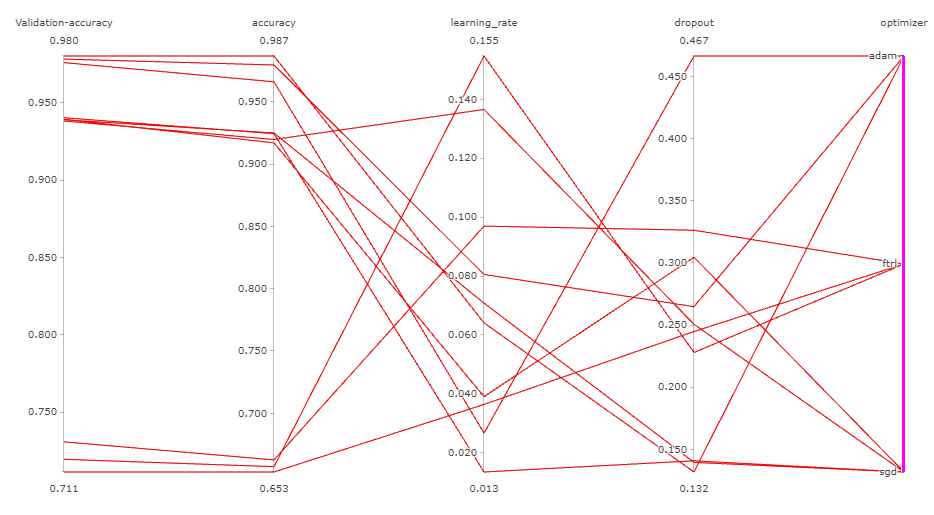
실험을 클릭하면 Trial 별로 선정된 하이퍼 파라미터에 대한 그래프가 나옵니다.
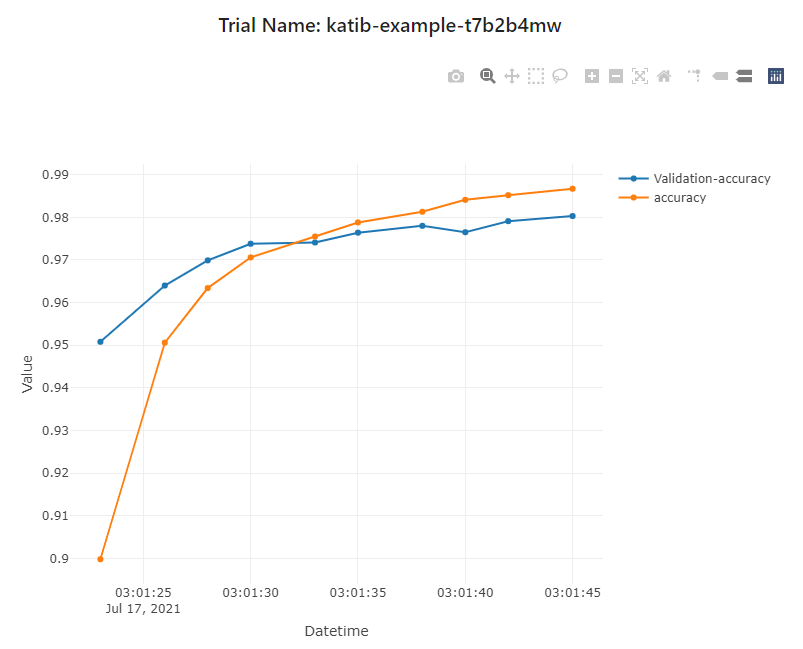
아래 테이블에서 trialName 을 클릭하면 epoch 진행됨에 따라 Objective 가 어떻게 변하는지 확인할 수 있습니다.
정리
- 하이퍼 파라미터 튜닝을 할 때 보통은 스크립트를 통해 하는데, Katib 를 쓰면
Ray처럼 병렬 수행이 가능하고 이에 대한 시각화도 잘 되어 있어서 좋습니다. - 아직은 편의성 부분이 많이 부족해보이네요. 대시보드에서 배포하는 메뉴가 있긴 한데, 직관적이지 못한 것 같습니다.
참고
- https://www.kangwoo.kr/2020/03/21/kubeflow-katib-%ED%95%98%EC%9D%B4%ED%8D%BC-%ED%8C%8C%EB%9D%BC%EB%AF%B8%ED%84%B0-%ED%8A%9C%EB%8B%9D/
